本文最后更新于 2026年4月17日 下午
最近参加了一个十米级内陆水体参量 AI
定量反演比赛,任务目标是根据光谱数据反演叶绿素 a
浓度、悬浮物浓度等指标。
光谱预处理我已经在前面两篇文章里整理过,这里就不重复展开了:
一、问题背景
刚开始接触这个任务时,我对“AI
定量反演”并没有很完整的认识,所以先查了一些文献,把问题的技术路径理清楚。常见方法大致可以分成三类:
经验统计模型:依赖叶绿素浓度与波段、波段组合之间的经验关系,通过回归分析建立反演公式。优点是简单直接,但可迁移性有限,往往需要针对具体水体做区域性校准。
半分析模型:基于辐射传输理论,把水体光学特性拆成吸收和散射两部分,再根据光谱反射率反演叶绿素浓度。它的物理意义更强,但参数复杂,对水体光学性质也比较敏感,实际应用时常受限。
机器学习模型:能够自动捕捉遥感光谱与水质参数之间的非线性关系,但也意味着模型选择、特征工程和超参数调优都会更重要,整个过程通常更费时。
我拿到数据后先试过经验模型和半分析模型,效果都不理想。回到比赛要求本身,既然是
AI
定量反演,最终还是得把重点放到机器学习建模上。后来我参考了一个很有启发性的案例:基于紫外差分光谱与神经网络相结合的一氧化氮痕量检测 ,它的数据类型和任务目标都和这次比赛比较接近,所以我就借鉴了它的思路来搭建模型。
二、为什么用遗传算法
模型搭起来之后,很快就遇到了一个很现实的问题:超参数对模型性能影响很大。起初我主要是盯着训练集表现,手动调整学习率、隐藏层神经元数量等参数。这个方法不是完全没用,确实能看到提升,但问题也很突出:调参非常耗时间,而且并不一定能碰到真正合适的组合。
于是我开始考虑自动搜索超参数。继续查资料后,我把目光放到了遗传算法上。它通过模拟自然选择、交叉和变异,在参数空间里做全局搜索,比较适合这种“目标函数不好手工求解析解,但可以通过验证集性能来评价”的问题。
遗传算法用来调参时,可以把一组超参数看成一个“个体”,再把验证集误差或损失函数看成适应度。整体思路很自然:
随机初始化一批超参数组合。
用每组参数训练模型,并计算验证集损失。
保留表现较好的组合。
对参数做交叉和变异,继续生成新组合。
重复迭代,直到达到终止条件。
这样做的好处是,超参数搜索不再完全依赖人工经验,而是变成一个可重复、可量化的优化过程。这里我使用的是
scikit-opt
来实现遗传算法,它的接口比较直接,适合快速把一个优化问题跑起来。
三、先看一个简单例子
在正式做超参数搜索之前,先看一个最基础的遗传算法例子,帮助理解它的调用方式。
1. 定义目标函数
下面这个例子是经典的 Schaffer
函数,主要用来演示优化算法如何搜索最小值。
1 2 3 4 5 6 7 8 9 import numpy as npdef schaffer (p ):"""一个带有多个局部极小值的测试函数。""" return 0.5 + (np.square(np.sin(part1)) - 0.5 ) / np.square(1 + 0.001 * part2)
2. 运行遗传算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from sko.GA import GA2 ,50 ,800 ,0.001 ,1 , -1 ],1 , 1 ],1e-7 ,print ("best_x:" , best_x)print ("best_y:" , best_y)
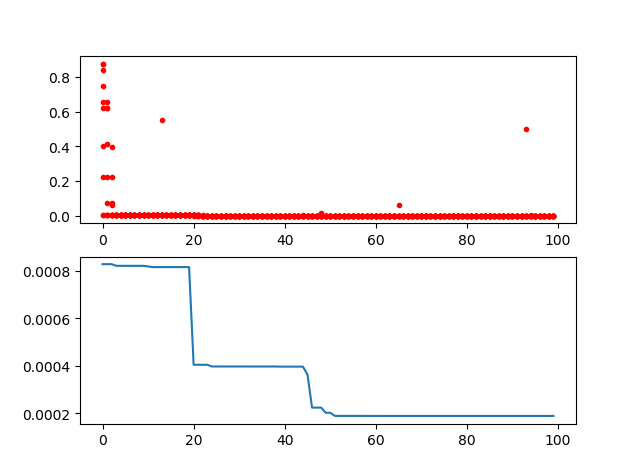
3. 查看优化过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import pandas as pdimport matplotlib.pyplot as plt2 , 1 , figsize=(8 , 6 ))0 ].plot(Y_history.index, Y_history.values, "." , color="red" )0 ].set_title("Each generation's fitness" )min (axis=1 ).cummin().plot(kind="line" , ax=ax[1 ])1 ].set_title("Best fitness so far" )
这个例子很简单,但它已经把核心流程说明白了:先定义目标函数,再让遗传算法去搜索最优解。
四、把遗传算法用于超参数优化
理解了基本用法之后,就可以把它迁移到模型调参上了。我的做法是把一组超参数编码成一个向量,让遗传算法直接搜索这个向量。这里为了演示,先把问题简化为“搜索多层感知机每一层的神经元数量”。
1. 读取数据并划分数据集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitr"data.xlsx" None )min ()) / (data.max () - data.min ())0.2 ,42 ,
2. 封装数据集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from paddle.io import Dataset, DataLoaderclass MyDataset (Dataset ):def __init__ (self, data_frame ):super ().__init__()self .features = data_frame.iloc[:, :-1 ].values.astype("float32" )self .labels = data_frame.iloc[:, -1 ].values.astype("float32" )def __getitem__ (self, index ):return self .features[index], self .labels[index]def __len__ (self ):return len (self .features)32 , shuffle=True )32 , shuffle=False )
3. 定义回归模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import paddle1 ] - 1 class Regressor (paddle.nn.Layer):def __init__ (self, hidden_nodes ):super ().__init__()self .fc1 = paddle.nn.Linear(input_dim, hidden_nodes[0 ])self .fc2 = paddle.nn.Linear(hidden_nodes[0 ], hidden_nodes[1 ])self .fc3 = paddle.nn.Linear(hidden_nodes[1 ], hidden_nodes[2 ])self .fc4 = paddle.nn.Linear(hidden_nodes[2 ], hidden_nodes[3 ])self .fc5 = paddle.nn.Linear(hidden_nodes[3 ], hidden_nodes[4 ])self .fc6 = paddle.nn.Linear(hidden_nodes[4 ], 1 )self .relu = paddle.nn.ReLU()def forward (self, inputs ):self .relu(self .fc1(inputs))self .relu(self .fc2(x))self .relu(self .fc3(x))self .relu(self .fc4(x))self .relu(self .fc5(x))return self .fc6(x)
4. 定义适应度函数
适应度函数是遗传算法的核心。这里我直接用验证集最后一个 epoch
的损失作为目标,损失越小,说明这组超参数越好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from sko.GA import GAclass LossCallback (paddle.callbacks.Callback):def __init__ (self ):super ().__init__()self .val_losses = []def on_eval_end (self, logs=None ):or {}self .val_losses.append(logs.get("loss" ))def loss_func (params ):max (1 , int (x)) for x in params]0.01 , parameters=model.parameters()),300 ,0 ,return loss_log.val_losses[-1 ][0 ]
5. 开始搜索超参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ga = GA(5 ,4 ,5 ,0.15 ,1 , 1 , 1 , 1 , 1 ],10 , 10 , 10 , 10 , 10 ],1 ,print ("best_x:" , best_x)print ("best_y:" , best_y)
搜索完成后,就可以把 best_x
代入模型,按这组超参数重新训练,再比较最终表现。
五、一些实践体会
遗传算法不是万能的,但它很适合这种“搜索空间大、人工调参成本高、目标函数又能直接评估”的场景。对我来说,它最大的价值不是一定能找到“绝对最优”,而是能先把一组比较靠谱的参数组合筛出来,减少大量重复试错。
另外,超参数优化时要注意两点:
目标函数计算成本会比较高,因为每次评估都要训练模型。
不要把搜索空间设得过于宽泛,否则迭代次数有限时很难真正收敛到有意义的区域。
后来我也看了其他超参数优化方案,比如 NNI 。它也是一个不错的选择,只是当时比赛时间比较紧,就没有继续展开尝试了。
六、总结
超参数调优不应该只靠手感。只要目标函数定义清楚,遗传算法这类启发式搜索方法就能把原本很费人工的过程自动化掉。
对于这个光谱反演任务,遗传算法做了两件事:
把调参过程标准化。
让我更系统地理解模型结构和验证集表现之间的关系。
后面如果再遇到类似问题,我会优先考虑先把搜索空间设计好,再让算法去跑,而不是一开始就靠经验盲调。